
什么样的聚类效果好?
聚类结果的簇内相似度高,且簇间相似度低
聚类性能度量
外部指标:结果与某个参考模型作比较,如Jaccard系数,FM指数,Rand指数,
内部指标:直接考察聚类结果,如DB指数,DI指数
计算距离
闵可夫斯基距离和VDM距离结合,可以计算有序属性和无序属性
sklearn聚类
- 参考:
- scikit-learn主要由分类、回归、聚类和降维四大部分组成,其中分类和回归属于有监督学习范畴,聚类属于无监督学习范畴,降维适用于有监督学习和无监督学习。scikit-learn的结构示意图如下所示:
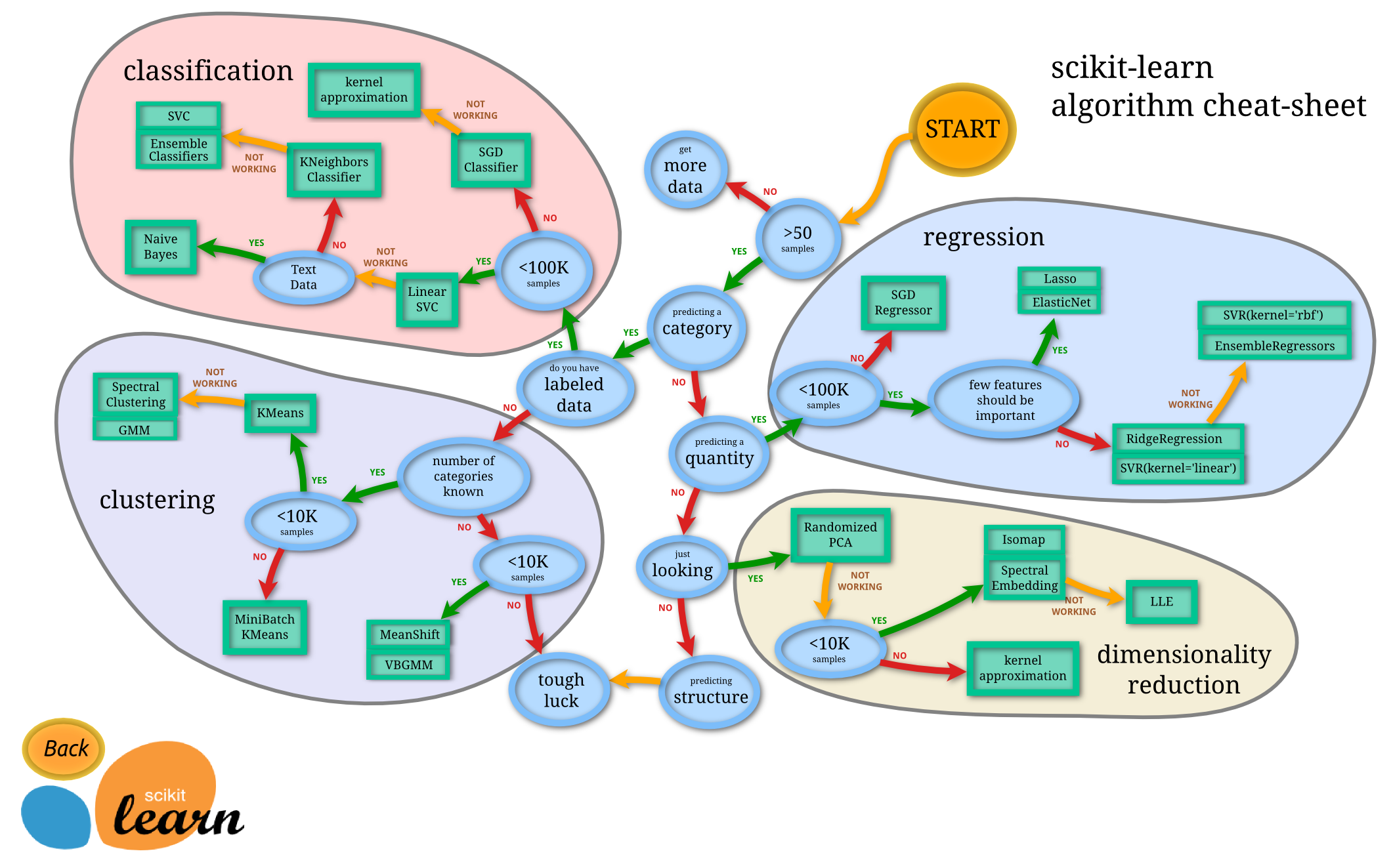
- scikit-learn中的聚类算法主要有:
- K-Means(cluster.KMeans)
- AP聚类(cluster.AffinityPropagation)
- 均值漂移(cluster.MeanShift)
- 层次聚类(cluster.AgglomerativeClustering)
- DBSCAN(cluster.DBSCAN)
- BRICH(cluster.Brich)
- 谱聚类(cluster.Spectral.Clustering)
- 高斯混合模型(GMM)∈期望最大化(EM)算法(mixture.GaussianMixture)
K-Means
1.1 算法描述
- 随机选择k个中心
- 遍历所有样本,把样本划分到距离最近的一个中心
- 划分之后就有K个簇,计算每个簇的平均值作为新的质心
- 重复步骤2,直到达到停止条件
- 停止条件:
- 聚类中心不再发生变化;所有的距离最小;迭代次数达到设定值,
- 代价函数:误差平方和
1.2 算法优缺点
优点:
- 算法容易理解,聚类效果不错
- 具有出色的速度
- 当簇近似高斯分布时,效果比较好
缺点:
- 需要自己确定K值,k值的选定是比较难确定
- 对初始中心点敏感
- 不适合发现非凸形状的簇或者大小差别较大的簇
- 特殊值/离群值对模型的影响比较大
- 从数据先验的角度来说,在 Kmeans 中,我们假设各个 cluster 的先验概率是一样的,但是各个 cluster 的数据量可能是不均匀的。举个例子,cluster A 中包含了10000个样本,cluster B 中只包含了100个。那么对于一个新的样本,在不考虑其与A cluster、 B cluster 相似度的情况,其属于 cluster A 的概率肯定是要大于 cluster B的。
1.3 效果评价
聚类结果的簇内相似度高,且簇间相似度低
常见方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index(CH指标,越大越好)
Silhouette Coefficient:
$$s(i)=\frac{b(i)-a(i)}{max(a(i),b(i))}$$
其中a(i)是样本$i$到同类所有样本的平均距离,b(i)是到其他某类所有样本的平均距离
- si接近1,则说明样本i聚类合理;
- si接近-1,则说明样本i更应该分类到另外的簇;
- 若si 近似为0,则说明样本i在两个簇的边界上。
Calinski-Harabasz Index
类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。实例代码:
|
|
python实现KMeans
|
|
LVQ算法
学习向量量化,随机选择有标记训练样本,找出距离最近的原型向量,根据两者的类别标记是否相同来对原型向量进行相应的更新(靠拢或者远离)。
高斯混合聚类
初始化模型参数,计算各混合分布的后验概率,重新计算新均值向量,新协方差矩阵,新混合系数,不断迭代。
密度聚类算法
DBSCAN
基于密度的空间聚类方法
簇:由密度可达关系导出的最大的密度相连样本集合。
DBSCAN的聚类是一个不断生长的过程。先找到一个核心对象,从整个核心对象出发,找出它的直接密度可达的对象,再从这些对象出发,寻找它们直接密度可达的对象,一直重复这个过程,直至最后没有可寻找的对象了,那么一个簇的更新就完成了。也可以认为,簇是所有密度可达的点的集合。
两个参数:
- Eps邻域半径(epsilon,小量,小的值)
- MinPts(minimum number of points required to form a cluster)定义核心点时的阈值。
几个概念:
$\epsilon$ 邻域: 对于样本$x_j$,包含D中与$x_j$样本距离不大于$\epsilon$的样本
核心对象:对于任一样本点,如果其 $\epsilon$ 邻域内至少包含MinPts个样本点,那么这个样本点就是核心对象。(一个点)
- 直接密度可达:如果一个样本点p处于一个核心对象q的Eps邻域内,则称该样本点p从对象q出发时是直接密度可达的。
- 密度相连:对于样本点p和q,如果存在核心对象m,使得p、p均由m直接密度可达,则称p和q密度相连。
优点:
- 不需要指定cluster的数目
- 聚类的形状可以是任意的
- 能找出数据中的噪音,对噪音不敏感
- 算法应用参数少,只需要两个
- 聚类结果几乎不依赖于节点的遍历顺序
缺点:
- 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
- DBSCAN算法的聚类效果依赖于距离公式的选取,实际中常用的距离是欧几里得距离,由于‘维数灾难’,距离的度量标准已变得不再重要。(分类器的性能随着特征数量的增加而不断提升,但过了某一值后,性能不升反而下降,这种现象称为维数灾难。对于维度灾难的理解:维度灾难的理解)
- 不适合数据集中密度差异很大的情形,因为这种情形,参数Eps,MinPts不好选择。(个人理解,如果是密度大的,你选一个小的邻域半径就可以把这些数据点聚类,但对于那些密度小的数据点,你设置的小的邻域半径,并不能把密度小的这些点给全部聚类。)
|
|
层次聚类算法
层次聚类试图在不同层次对数据集进行划分,形成树的聚类结构。
AGNES算法在树状图上的特定层次进行分割,得到相应的簇划分结果。

